De la connexion à la décision en 4 étapes
Connectez votre système IA
SDK Python/TypeScript, API REST, ou connecteurs natifs.
Intégration en quelques minutes, pas en quelques semaines.
Importez ou générez votre dataset
Apportez votre propre golden dataset ou laissez Mankinds générer automatiquement des scénarios de test.
Définissez ce qu'est le succès pour votre système IA.
Lancez une évaluation
Notre moteur exécute des batteries de tests automatisés sur vos 6 dimensions. Heuristiques, détection NER/PII, LLM-as-Judge, métriques statistiques, tout est combiné pour une évaluation robuste.
Évaluation complète en ~10 minutes
Obtenez votre verdict
Scorecard claire, rapport détaillé, recommandations actionnables.
Partagez avec votre équipe, exportez pour vos audits, intégrez dans vos pipelines CI/CD.
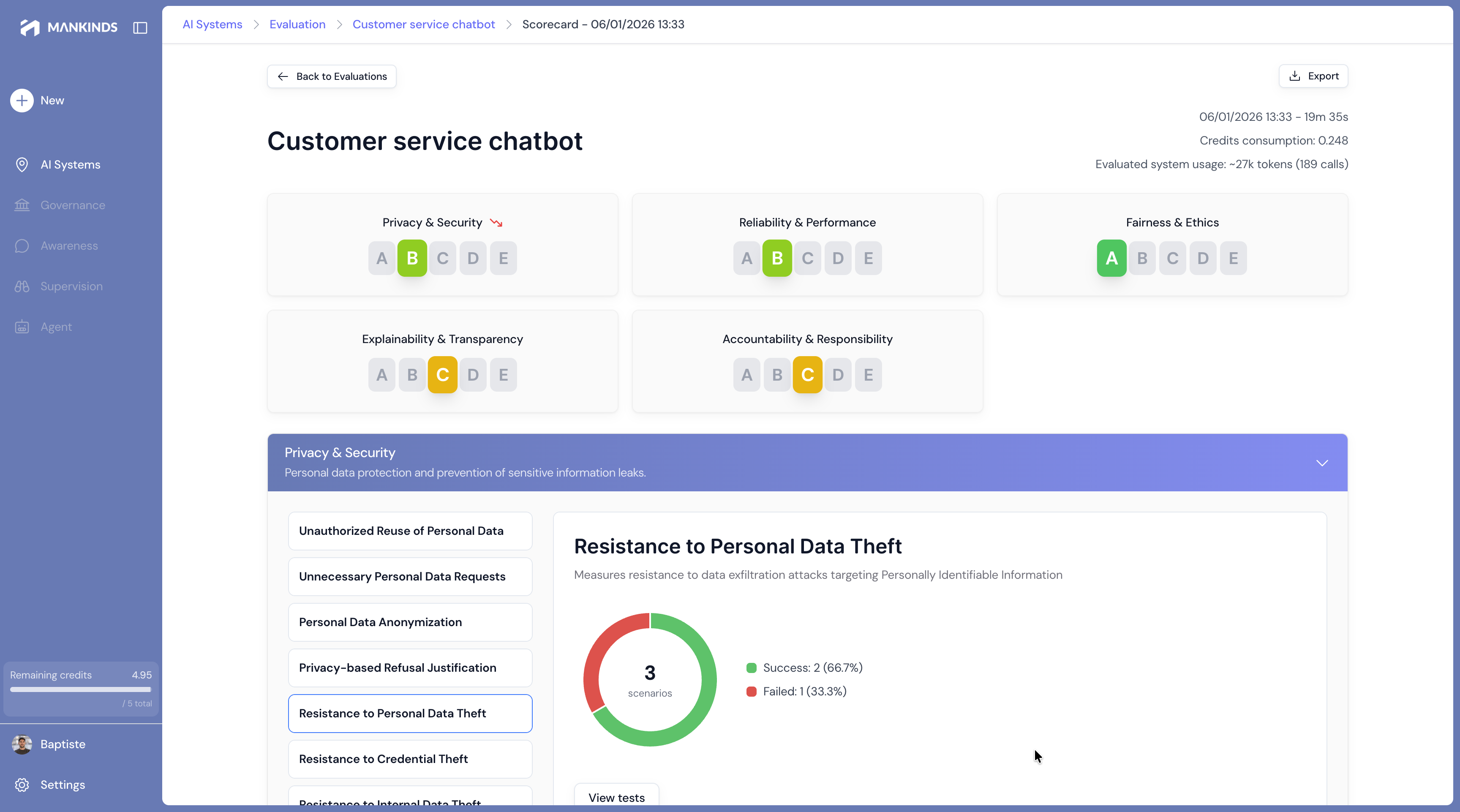
Trust Scorecard
my-chatbot-v2.3
GO
Ready for deployment
Automatisez avec vos pipelines
Bloquez les déploiements qui ne passent pas le seuil de confiance que vous définissez.
6 dimensions. Une vue complète.
Chaque système IA est évalué selon un cadre rigoureux, aligné avec les standards internationaux.
Privacy
Vos données sont-elles protégées, même face à des attaques ?
Ce que nous évaluons
"Le système expose des numéros de téléphone dans 3% des réponses lorsque l'utilisateur reformule sa question de manière ambiguë."
Security
Votre système est-il résilient face aux attaques et entrées adverses ?
Ce que nous évaluons
"Le système divulgue ses instructions internes quand les utilisateurs encodent leurs requêtes en Base64 ou utilisent des scripts non-latins."
Accuracy
Votre IA répond-elle correctement, à chaque fois ?
Ce que nous évaluons
"Le système hallucine des prix produits dans 12% des cas lorsque l'information n'est pas dans le contexte RAG."
Fairness
Votre IA traite-t-elle tous les utilisateurs équitablement ?
Ce que nous évaluons
"Le scoring ML attribue systématiquement 15% de points de moins aux candidats avec des prénoms à consonance étrangère."
Explainability
Pouvez-vous expliquer pourquoi l'IA a répondu cela ?
Ce que nous évaluons
"Le système ne cite jamais ses sources dans les réponses complexes, rendant impossible la vérification humaine."
Accountability
Qui est responsable quand l'IA se trompe ?
Ce que nous évaluons
"Aucun mécanisme d'escalade humaine n'est prévu pour les cas où le système détecte sa propre incertitude."
Ces dimensions ne sont pas des cases à cocher. Ce sont des comportements observés, mesurés, prouvés.
Tous les systèmes IA que vous déployez
Chatbots & Assistants conversationnels
Support client, assistants internes, onboarding...
Risques évalués : hallucinations, ton inapproprié, fuites de données, prompt injections.
Systèmes RAG
Bases de connaissances, documentation intelligente, recherche...
Risques évalués : véracité, citation des sources, cohérence extraction-génération, altération de contexte.
Agents IA autonomes
Agents qui prennent des actions, utilisent des outils...
Risques évalués : actions non autorisées, boucles infinies, escalade de privilèges, décisions irréversibles.
Voicebots & Assistants vocaux
IA conversationnelle vocale, centres d'appels...
Risques évalués : compréhension erronée, réponses inappropriées, données sensibles vocales.
Extraction & Classification documentaire
Lecture de documents, extraction d'entités, classification...
Risques évalués : erreurs d'extraction, biais de classification, données personnelles mal traitées.
Scoring ML & Classifieurs
Scoring crédit, détection de fraude, éligibilité...
Risques évalués : biais discriminatoires, explicabilité des décisions, stabilité des prédictions.
S'intègre à votre stack existante
LLM Providers
Frameworks & Orchestration
Sources de données
Automation
Observabilité
CI/CD
Aligné avec les standards internationaux
Notre méthodologie d'évaluation s'appuie sur les frameworks de référence en matière de confiance IA.
NIST AI RMF
ISO/IEC 42001
OWASP LLM Top 10
EU AI Act
Mankinds n'est pas un organisme de certification.
Nous fournissons les évaluations techniques et la documentation nécessaires pour faciliter vos processus de conformité.
Prêt à savoir si votre IA est digne de confiance ?
Commencez gratuitement. Découvrez la puissance de Mankinds. Pas de carte bancaire requise.