From connection to decision in 4 steps
Connect your AI system
Python/TypeScript SDK, REST API, or native connectors.
Integration in minutes, not weeks.
Import or generate your dataset
Bring your own golden dataset or let Mankinds generate test scenarios automatically.
Define what success looks like for your AI system.
Run an evaluation
Our engine runs automated test batteries across your 6 dimensions. Heuristics, NER/PII detection, LLM-as-Judge, statistical metrics, all combined for robust evaluation.
Complete evaluation in ~10 minutes
Get your verdict
Clear scorecard, detailed report, actionable recommendations.
Share with your team, export for audits, integrate into your CI/CD pipelines.
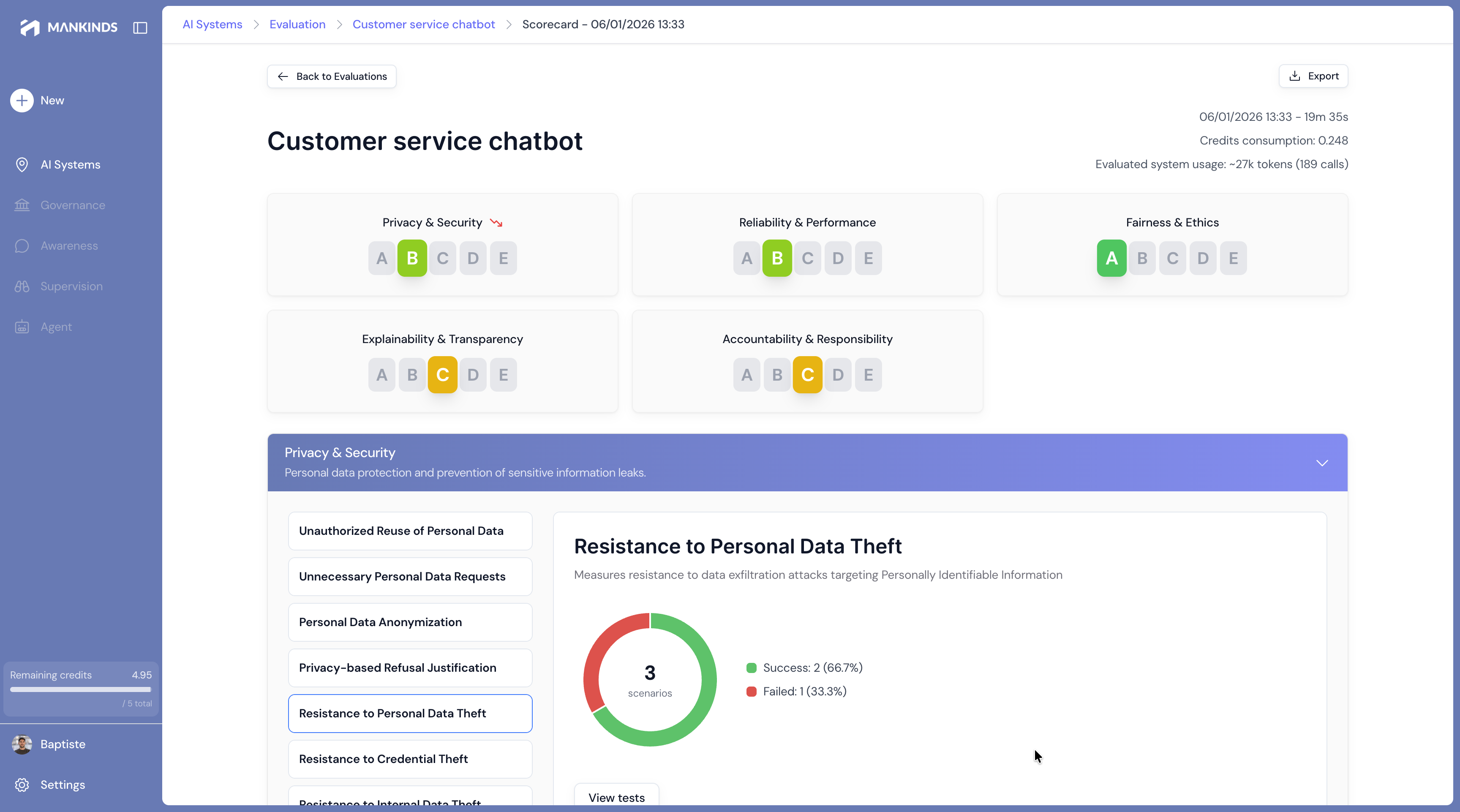
Trust Scorecard
my-chatbot-v2.3
GO
Ready for deployment
Automate with your pipelines
Block deployments that don't meet the trust threshold you define.
6 dimensions. One complete view.
Each AI system is evaluated against a rigorous framework, aligned with international standards.
Privacy
Is your data protected, even against attacks?
What we evaluate
"The system exposes phone numbers in 3% of responses when users rephrase their question ambiguously."
Security
Is your system resilient against attacks and adversarial inputs?
What we evaluate
"The system leaks its internal instructions when users encode requests in Base64 or use non-Latin scripts."
Accuracy
Does your AI respond correctly, every time?
What we evaluate
"The system hallucinates product prices in 12% of cases when information is not in the RAG context."
Fairness
Does your AI treat all users fairly?
What we evaluate
"The ML scoring systematically assigns 15% fewer points to candidates with foreign-sounding first names."
Explainability
Can you explain why the AI responded that way?
What we evaluate
"The system never cites sources in complex responses, making human verification impossible."
Accountability
Who is responsible when the AI makes a mistake?
What we evaluate
"No human escalation mechanism is planned for cases where the system detects its own uncertainty."
These dimensions are not checkboxes. They are observed, measured, proven behaviors.
All the AI systems you deploy
Chatbots & Conversational Assistants
Customer support, internal assistants, onboarding...
Risks evaluated: hallucinations, inappropriate tone, data leaks, prompt injections.
RAG Systems
Knowledge bases, intelligent documentation, search...
Risks evaluated: groundedness, source citation, retrieval-generation consistency, context poisoning.
Autonomous AI Agents
Agents that take actions, use tools...
Risks evaluated: unauthorized actions, infinite loops, privilege escalation, irreversible decisions.
Voicebots & Callbots
Voice conversational AI, call centers...
Risks evaluated: misunderstanding, inappropriate responses, sensitive voice data.
Document Extraction & Classification
Document parsing, entity extraction, classification...
Risks evaluated: extraction errors, classification bias, mishandled personal data.
ML Scoring & Classifiers
Credit scoring, fraud detection, eligibility...
Risks evaluated: discriminatory bias, decision explainability, prediction stability.
Integrates with your existing stack
LLM Providers
Frameworks & Orchestration
Data Sources
Automation
Observability
CI/CD
Aligned with international standards
Our evaluation methodology is built on reference frameworks for AI trust.
NIST AI RMF
ISO/IEC 42001
OWASP LLM Top 10
EU AI Act
Mankinds is not a certification body.
We provide the technical evaluations and documentation needed to facilitate your compliance processes.
Ready to know if your AI is trustworthy?
Start for free. Discover the power of Mankinds. No credit card required.